6 Cleaning & Reshaping
Updated for S2026? No.
When we talk about cleaning data, there are 4 broad steps:
- Reshaping and tidying
- Filtering and subsetting
- Transforming/re-coding/cleaning variables
- Aggregating and/or merging the data
Steps 2 and 3 we talked about last week, and we will soon talk about step 4.
Step 1 is what we are going to talk about today, and is a topic with a good amount of complexity.
6.1 Reshaping
6.1.1 Unit of Analysis
I have discussed before the importance of knowing the unit of analysis of the data you are working with. This is really going to come into play now.
Once again, to get the unit of analysis ask: what does each row uniquely represent?
Last week when we were working with the ACS data this was very clear as each row represented one of the approximately 3000 counties in the United States.
But this can get more complicated.
Compare this dataset:
#> Warning: Missing `trust` will be set to FALSE by default
#> for RDS in 2.0.0.
#> county date_1_1_2021 date_1_2_2021 date_1_3_2021
#> 1 c1 990 9 215
#> 2 c2 140 1000 305
#> 3 c3 797 323 141
#> 4 c4 343 34 645
#> date_1_4_2021
#> 1 646
#> 2 4
#> 3 260
#> 4 785To this dataset:
#> # A tibble: 16 × 3
#> county date ` covid.cases`
#> <chr> <chr> <dbl>
#> 1 c1 date_1_1_2021 990
#> 2 c1 date_1_2_2021 9
#> 3 c1 date_1_3_2021 215
#> 4 c1 date_1_4_2021 646
#> 5 c2 date_1_1_2021 140
#> 6 c2 date_1_2_2021 1000
#> 7 c2 date_1_3_2021 305
#> 8 c2 date_1_4_2021 4
#> 9 c3 date_1_1_2021 797
#> 10 c3 date_1_2_2021 323
#> 11 c3 date_1_3_2021 141
#> 12 c3 date_1_4_2021 260
#> 13 c4 date_1_1_2021 343
#> 14 c4 date_1_2_2021 34
#> 15 c4 date_1_3_2021 645
#> 16 c4 date_1_4_2021 785First notice: these two datasets contain the exact same information. This is data on covid cases in 4 counties for the first 4 days of 2021. The same 16 case numbers exist in both datasets.
What is the unit of analysis of the first dataset, and what is the unit of analysis of the second dataset?
The first dataset has county as the unit of observation. Each row is a county and every county is only in the dataset once.
The second dataset also has county as a variable, but does county uniquely identify each row? No! There are 4 rows for each county, one for each date. In this case the unit of analysis of the data is county-date.
These two datasets, representing the same data, have two different units of analysis.
More broadly, we might consider these two datasets as representing the same data in both “Wide” and “Long” formats.
- Wide data has one observation per row, and columns have data for a particular variable spread out over columns.
- Long data might have observations occur in several rows, but each variable only exists in only one column.
In the above example, the first dataset was wide with respect to county. There is only one row for county, but the data for covid cases was spread across several rows. The second dataset was long with respect to county. Each county existed across multiple rows, but case numbers are represented in only one column.
Here is another example:
#> Warning: Missing `trust` will be set to FALSE by default
#> for RDS in 2.0.0.
#> district candidate votes
#> 1 1 Biden 1362
#> 2 1 Trump 1073
#> 3 2 Biden 1453
#> 4 2 Trump 1147
#> 5 3 Biden 1481
#> 6 3 Trump 1076
#> 7 4 Biden 1072
#> 8 4 Trump 1495
#> 9 5 Biden 1372
#> 10 5 Trump 1286What is the unit of analysis of this data? Can it be district? No! there are two rows for every district so district does not uniquely identify rows. What about candidate? No! The candidate also does not uniquely identify rows. Here district-candidate uniquely identifies rows.
And once again, we can represent the same information like this:
#> # A tibble: 5 × 3
#> district Biden Trump
#> <dbl> <dbl> <dbl>
#> 1 1 1362 1073
#> 2 2 1453 1147
#> 3 3 1481 1076
#> 4 4 1072 1495
#> 5 5 1372 1286This is the same 10 vote counts now represented in a wide format.
The first dataset is long with respect to district: districts occurred across several rows, but the vote information only existed in one column.
The second dataset is wide with respect to district: districts only exist in one row, but now the vote information is spread across multiple rows.
OK, let’s get even more wild: how would we charecterize this dataset:
#> # A tibble: 2 × 6
#> candidate `1` `2` `3` `4` `5`
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 Biden 1362 1453 1481 1072 1372
#> 2 Trump 1073 1147 1076 1495 1286This is the same information again! Now presented in a new way. Now the unit of analysis is candidate. We would say that this data is wide with respect to candidate. Each candidate is in only one row, and the vote information is spread across multiple columns, one for each district.
Which of these is the “right” way to display this data? There is no such thing! None is right or wrong. The three different versions of this vote data are all helpful for different tasks. Knowing and understanding a particular task requires, and being able to use R to switch between these differently shaped datasets is what is key.
I won’t lie: reshaping is somewhat tricky and it takes me a bit more trial and error to do it compared with other tasks. But it is also an invaluable step in the data cleaning process.
6.1.2 Reshaping from Wide to Long
Let’s jump into how we do reshaping. The tools we are using are also from the tidyr package that we used last week, so we will have to load that in.
First let’s load in the first example from above:
#Code to be learned starts here
library(tidyr)
dat <- rio::import("https://github.com/marctrussler/IDS-Data/raw/main/WideExample.RDS")
#> Warning: Missing `trust` will be set to FALSE by default
#> for RDS in 2.0.0.
dat
#> county date_1_1_2021 date_1_2_2021 date_1_3_2021
#> 1 c1 990 9 215
#> 2 c2 140 1000 305
#> 3 c3 797 323 141
#> 4 c4 343 34 645
#> date_1_4_2021
#> 1 646
#> 2 4
#> 3 260
#> 4 785We are starting here with wide data that we want to make long. There is one row for each of the 4 counties, and the information for cases is spread across 4 columns. What we want is a dataset where the unit of observation is county-date, such that county is duplicated 4 times for every county. Like this:
#> # A tibble: 16 × 3
#> county date covid.cases
#> <chr> <chr> <dbl>
#> 1 c1 date_1_1_2021 990
#> 2 c1 date_1_2_2021 9
#> 3 c1 date_1_3_2021 215
#> 4 c1 date_1_4_2021 646
#> 5 c2 date_1_1_2021 140
#> 6 c2 date_1_2_2021 1000
#> 7 c2 date_1_3_2021 305
#> 8 c2 date_1_4_2021 4
#> 9 c3 date_1_1_2021 797
#> 10 c3 date_1_2_2021 323
#> 11 c3 date_1_3_2021 141
#> 12 c3 date_1_4_2021 260
#> 13 c4 date_1_1_2021 343
#> 14 c4 date_1_2_2021 34
#> 15 c4 date_1_3_2021 645
#> 16 c4 date_1_4_2021 785So we want to take the data that is currently spread across the date columns and to put them in a new column called “covid.cases”. We are also going to create a new column called “date” to put the date information in.
To go from wide to long data we use the pivot_longer() command. Like the separate() command we used last week from the tidyr package, to use this command we enter our full dataset and it returns a full datset back.
We are going to give pivot_longer() three pieces of information:
cols=The columns we are going to operate on.names_to=The name of the new column we are going to put the current column names into.values_to=The name of the new column we are going to put the covid case numbers into.
This makes a bit more sense when we actually just do it:
Applying to this example:
pivot_longer(dat,
cols = "date_1_1_2021":"date_1_4_2021",
names_to = "date",
values_to = "covid.cases")
#> # A tibble: 16 × 3
#> county date covid.cases
#> <chr> <chr> <dbl>
#> 1 c1 date_1_1_2021 990
#> 2 c1 date_1_2_2021 9
#> 3 c1 date_1_3_2021 215
#> 4 c1 date_1_4_2021 646
#> 5 c2 date_1_1_2021 140
#> 6 c2 date_1_2_2021 1000
#> 7 c2 date_1_3_2021 305
#> 8 c2 date_1_4_2021 4
#> 9 c3 date_1_1_2021 797
#> 10 c3 date_1_2_2021 323
#> 11 c3 date_1_3_2021 141
#> 12 c3 date_1_4_2021 260
#> 13 c4 date_1_1_2021 343
#> 14 c4 date_1_2_2021 34
#> 15 c4 date_1_3_2021 645
#> 16 c4 date_1_4_2021 785We gave this command the name of the dataset we are pivoting. We told it the columns that we are going to convert into long data. We told it what we wanted the new column to be called that contains the old column headers. Finally we told it the name of the column that will contain the actual data.
There is nothing special about the names I gave it in this step, I could do:
pivot_longer(dat,
cols = "date_1_1_2021":"date_1_4_2021",
names_to = "batman",
values_to = "robin")
#> # A tibble: 16 × 3
#> county batman robin
#> <chr> <chr> <dbl>
#> 1 c1 date_1_1_2021 990
#> 2 c1 date_1_2_2021 9
#> 3 c1 date_1_3_2021 215
#> 4 c1 date_1_4_2021 646
#> 5 c2 date_1_1_2021 140
#> 6 c2 date_1_2_2021 1000
#> 7 c2 date_1_3_2021 305
#> 8 c2 date_1_4_2021 4
#> 9 c3 date_1_1_2021 797
#> 10 c3 date_1_2_2021 323
#> 11 c3 date_1_3_2021 141
#> 12 c3 date_1_4_2021 260
#> 13 c4 date_1_1_2021 343
#> 14 c4 date_1_2_2021 34
#> 15 c4 date_1_3_2021 645
#> 16 c4 date_1_4_2021 785(But I wouldn’t do that).
Like separate() from last week, pivot_longer() takes our whole dataset as an argument and outputs a whole dataset. As such, we need to save the output:
dat.l <- pivot_longer(dat,
cols = "date_1_1_2021":"date_1_4_2021",
names_to = "date",
values_to = "covid.cases")
dat.l
#> # A tibble: 16 × 3
#> county date covid.cases
#> <chr> <chr> <dbl>
#> 1 c1 date_1_1_2021 990
#> 2 c1 date_1_2_2021 9
#> 3 c1 date_1_3_2021 215
#> 4 c1 date_1_4_2021 646
#> 5 c2 date_1_1_2021 140
#> 6 c2 date_1_2_2021 1000
#> 7 c2 date_1_3_2021 305
#> 8 c2 date_1_4_2021 4
#> 9 c3 date_1_1_2021 797
#> 10 c3 date_1_2_2021 323
#> 11 c3 date_1_3_2021 141
#> 12 c3 date_1_4_2021 260
#> 13 c4 date_1_1_2021 343
#> 14 c4 date_1_2_2021 34
#> 15 c4 date_1_3_2021 645
#> 16 c4 date_1_4_2021 7856.1.3 Reshaping from Wide to Long
How do we put this back into its original format?
We can do that with the (obviously) pivot_wider() command. We can really think about this as doing the opposite to what we saw above, and the names of the arguments reflects that. We will tell this command:
names_from=the column that we want to use to name the new columns in our wider dataset.values_from=the column that we want to use to pull the values that will go into those new columns.
Putting that in action:
So for this case:
dat.w <- pivot_wider(dat.l,
names_from = "date",
values_from = "covid.cases")
dat.w
#> # A tibble: 4 × 5
#> county date_1_1_2021 date_1_2_2021 date_1_3_2021
#> <chr> <dbl> <dbl> <dbl>
#> 1 c1 990 9 215
#> 2 c2 140 1000 305
#> 3 c3 797 323 141
#> 4 c4 343 34 645
#> # ℹ 1 more variable: date_1_4_2021 <dbl>And we are back to where we started.
In contrast to pivot_longer, it does matter what variable names we put into pivot_wider because we are referencing actual variables in the dataset. So if we tried:
# pivot_wider(dat.l,
# names_from = "month",
# values_from = "cases")We get an error.
Let’s try to do something else with the information we have. What if we wanted to take our long dataset and convert it to a wide dataset where the rows are dates, like this:
#> # A tibble: 4 × 5
#> date c1 c2 c3 c4
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 date_1_1_2021 990 140 797 343
#> 2 date_1_2_2021 9 1000 323 34
#> 3 date_1_3_2021 215 305 141 645
#> 4 date_1_4_2021 646 4 260 785We just need to change around what variables get referenced where. We now want the rows of the wide dataset to be date, and the column names will now be the counties.
pivot_wider(dat.l,
names_from = "county",
values_from = "covid.cases")
#> # A tibble: 4 × 5
#> date c1 c2 c3 c4
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 date_1_1_2021 990 140 797 343
#> 2 date_1_2_2021 9 1000 323 34
#> 3 date_1_3_2021 215 305 141 645
#> 4 date_1_4_2021 646 4 260 785Let’s think about the second dataset
dat2
#> district candidate votes
#> 1 1 Biden 1362
#> 2 1 Trump 1073
#> 3 2 Biden 1453
#> 4 2 Trump 1147
#> 5 3 Biden 1481
#> 6 3 Trump 1076
#> 7 4 Biden 1072
#> 8 4 Trump 1495
#> 9 5 Biden 1372
#> 10 5 Trump 1286Here this is long data, we have districts spanning across multiple rows, one for each candidate.
We might want this to be wide data if we want a single summation of the election for each district.
Again, we need to provide the pivot_wider() command information about what what column we will use to make the new columns in the wide data and what column we will use to fill in values in those new columns:
dat2.w <- pivot_wider(dat2,
names_from ="candidate",
values_from = "votes")
dat2.w
#> # A tibble: 5 × 3
#> district Biden Trump
#> <dbl> <dbl> <dbl>
#> 1 1 1362 1073
#> 2 2 1453 1147
#> 3 3 1481 1076
#> 4 4 1072 1495
#> 5 5 1372 1286We went from the unit of analysis being district-candidates, to the unit of analysis being districts.
Then for example, we could calculate each candidates percent of the total vote:
dat2.w$total.votes <- dat2.w$Biden + dat2.w$Trump
dat2.w$perc.biden <- dat2.w$Biden/dat2.w$total.votes
dat2.w$perc.trump <- dat2.w$Trump/dat2.w$total.votes
dat2.w
#> # A tibble: 5 × 6
#> district Biden Trump total.votes perc.biden perc.trump
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 1 1362 1073 2435 0.559 0.441
#> 2 2 1453 1147 2600 0.559 0.441
#> 3 3 1481 1076 2557 0.579 0.421
#> 4 4 1072 1495 2567 0.418 0.582
#> 5 5 1372 1286 2658 0.516 0.484You don’t often want to delete data, but let’s say we just wanted to make a nice table and only wanted district, perc.biden, perc.trump, and to mak ethe values rounded.
You can delete variables:
dat2.table <- dat2.w
dat2.table$Biden <- NULL
dat2.table$Trump <- NULL
dat2.table$total.votes <- NULL
dat2.table
#> # A tibble: 5 × 3
#> district perc.biden perc.trump
#> <dbl> <dbl> <dbl>
#> 1 1 0.559 0.441
#> 2 2 0.559 0.441
#> 3 3 0.579 0.421
#> 4 4 0.418 0.582
#> 5 5 0.516 0.484We can also give a list of variables to keep and subset that way:
to.keep <- c("district","perc.biden","perc.trump")
dat2.table <- dat2.w[to.keep]
dat2.w <- dat2.w[to.keep]
dat2.table
#> # A tibble: 5 × 3
#> district perc.biden perc.trump
#> <dbl> <dbl> <dbl>
#> 1 1 0.559 0.441
#> 2 2 0.559 0.441
#> 3 3 0.579 0.421
#> 4 4 0.418 0.582
#> 5 5 0.516 0.484To round a variable we use…. round()
round(717.128210, 0)
#> [1] 717
dat2.table$perc.biden <- round(dat2.table$perc.biden*100,2)
dat2.table$perc.trump <- round(dat2.table$perc.trump*100,2)
dat2.table
#> # A tibble: 5 × 3
#> district perc.biden perc.trump
#> <dbl> <dbl> <dbl>
#> 1 1 55.9 44.1
#> 2 2 55.9 44.1
#> 3 3 57.9 42.1
#> 4 4 41.8 58.2
#> 5 5 51.6 48.4What if we wanted to study candidates, instead of districts?? It should be pretty clear what to do:
dat.2.candidates <- pivot_wider(dat2,
names_from = "district",
values_from = "votes")
dat.2.candidates
#> # A tibble: 2 × 6
#> candidate `1` `2` `3` `4` `5`
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 Biden 1362 1453 1481 1072 1372
#> 2 Trump 1073 1147 1076 1495 1286Again: there is nothing right or wrong about any of these datasets. All of them just present the same information in different ways. Translating in between them is what is important.
6.2 A Full Data Cleaning Example
In the second half of this week we are going to go through a full example of cleaning a dataset from start to finish.
library(tidyr)
library(lubridate)
#>
#> Attaching package: 'lubridate'
#> The following objects are masked from 'package:base':
#>
#> date, intersect, setdiff, unionIs there a relationship between age and voting for Trump among Millenials? We know that there is definitely a relationship in the population as a whole, but does that same logic extend to within an age group that is very anti Trump?
Could definitely see older millenials maybe being more concerned about taxes?
Today we are going to work with some survey data to ultimately answer that question, but we first have to clean that data to be able to work with it.
6.2.1 Reshaping and reformatting data
Today we’ll be working with Generation Forward survey data.
genfor <- rio::import("https://github.com/marctrussler/IDS-Data/raw/main/Genfor.RDS")
#> Warning: Missing `trust` will be set to FALSE by default
#> for RDS in 2.0.0.The unit of analysis we want to work with are individuals, which in this case are American millenials.
Is it the case that individuals in this dataset are uniquely identified in each row? What other things seem like they need to be cleaned?
head(genfor)
#> GENF_ID WEIGHT1 Q0 Q1 approval.party
#> 1 792562474 0.4921835398 2 2 democratic
#> 2 792562474 0.4921835398 2 2 republican
#> 3 794325578 1.2025737846 4 5 democratic
#> 4 794325578 1.2025737846 4 5 republican
#> 5 795569196 0.1318494446 1 5 democratic
#> 6 795569196 0.1318494446 1 5 republican
#> approval.value Q10A_1 Q10A_2 Q10A_3 Q10A_4 Q10A_5 Q10A_6
#> 1 3 0 0 0 0 0 0
#> 2 2 0 0 0 0 0 0
#> 3 3 0 0 0 0 0 0
#> 4 4 0 0 0 0 0 0
#> 5 2 0 0 0 0 0 0
#> 6 3 0 0 0 0 0 0
#> Q10A_7 Q10A_8 Q10A_9 Q10A_10 Q10A_11 Q10A_12 Q10A_13
#> 1 0 0 0 0 0 0 0
#> 2 0 0 0 0 0 0 0
#> 3 0 0 0 0 0 0 0
#> 4 0 0 0 0 0 0 0
#> 5 0 0 0 0 0 0 0
#> 6 0 0 0 0 0 0 0
#> Q10A_14 Q10A_15 Q10A_16 Q10A_17 Q10A_18 Q10A_19 Q10A_20
#> 1 0 0 1 0 0 0 0
#> 2 0 0 1 0 0 0 0
#> 3 0 0 0 0 0 0 0
#> 4 0 0 0 0 0 0 0
#> 5 0 0 0 0 0 0 0
#> 6 0 0 0 0 0 0 0
#> Q10A_21 Q10A_22 partyid7 date duration device
#> 1 0 0 5 2017-10-27 11 Desktop
#> 2 0 0 5 2017-10-27 11 Desktop
#> 3 1 0 4 2017-10-27 5 Smartphone
#> 4 1 0 4 2017-10-27 5 Smartphone
#> 5 0 1 3 2017-10-26 11 Smartphone
#> 6 0 1 3 2017-10-26 11 Smartphone
#> gender age educ state
#> 1 1 18 9 PA
#> 2 1 18 9 PA
#> 3 2 27 6 OK
#> 4 2 27 6 OK
#> 5 2 22 10 NC
#> 6 2 22 10 NC- There are two rows for every observation
- The contents of the Q10A variable are spread across 22 columns
- The column names are inconsistently formatted and not very descriptive
- Most of the variables could be cleaned up a bit so that they’re easier to interpret
Just as a reference for later, I’m going to save an original version of the dataset.
genfor.untouched <- genforJust as a proof of the above, we can compare the number of rows with how many unique entries there are for ID:
Let’s figure this out.
With regard to the approval variable, is the genforward data formatted as wide or long?
head(genfor[c("GENF_ID","approval.party","approval.value")])
#> GENF_ID approval.party approval.value
#> 1 792562474 democratic 3
#> 2 792562474 republican 2
#> 3 794325578 democratic 3
#> 4 794325578 republican 4
#> 5 795569196 democratic 2
#> 6 795569196 republican 3Notice that every value of row 1 equals the value in row 2, except for approval.party and approval.value.
genfor[1,] == genfor[2,]
#> GENF_ID WEIGHT1 Q0 Q1 approval.party approval.value
#> 1 TRUE TRUE TRUE TRUE FALSE FALSE
#> Q10A_1 Q10A_2 Q10A_3 Q10A_4 Q10A_5 Q10A_6 Q10A_7 Q10A_8
#> 1 TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
#> Q10A_9 Q10A_10 Q10A_11 Q10A_12 Q10A_13 Q10A_14 Q10A_15
#> 1 TRUE TRUE TRUE TRUE TRUE TRUE TRUE
#> Q10A_16 Q10A_17 Q10A_18 Q10A_19 Q10A_20 Q10A_21 Q10A_22
#> 1 TRUE TRUE TRUE TRUE TRUE TRUE TRUE
#> partyid7 date duration device gender age educ state
#> 1 TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUESo with respect to the “approval” variables genfor is a long dataset, where each observation (i.e. each survey respondent) has two rows of data. And their approval ratings for the Democratic and Republican parties are split across the two rows.
Our first step in cleaning the data will be to condense those two rows into one.
To do this, we’ll use the pivot_wider() function. We want each row to be GENF_ID. We want new columns based on approval.party, and we want the values in those new columns to come from approveal.value
genfor <- pivot_wider(genfor,
names_from = "approval.party",
values_from = "approval.value")
head(genfor)
#> # A tibble: 6 × 36
#> GENF_ID WEIGHT1 Q0 Q1 Q10A_1 Q10A_2 Q10A_3 Q10A_4
#> <dbl> <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 792562474 0.49218… 2 2 0 0 0 0
#> 2 794325578 1.20257… 4 5 0 0 0 0
#> 3 795569196 0.13184… 1 5 0 0 0 0
#> 4 803023033 0.82491… 2 2 1 0 0 0
#> 5 809729125 0.21490… 4 4 0 0 0 0
#> 6 812940493 0.86487… 1 5 0 0 1 0
#> # ℹ 28 more variables: Q10A_5 <dbl>, Q10A_6 <dbl>,
#> # Q10A_7 <dbl>, Q10A_8 <dbl>, Q10A_9 <dbl>,
#> # Q10A_10 <dbl>, Q10A_11 <dbl>, Q10A_12 <dbl>,
#> # Q10A_13 <dbl>, Q10A_14 <dbl>, Q10A_15 <dbl>,
#> # Q10A_16 <dbl>, Q10A_17 <dbl>, Q10A_18 <dbl>,
#> # Q10A_19 <dbl>, Q10A_20 <dbl>, Q10A_21 <dbl>,
#> # Q10A_22 <dbl>, partyid7 <dbl>, date <chr>, …Notice the other nice thing about the pivot_wider() function is that it ignored all variables that were the same across the two rows. The only thing that happened is that we got two new variables.
6.2.2 Dealing with individual variables that are spread across multiple columns
Now let’s deal with the Q10A variable. Let’s give it a quick look:
Occasionally (NOT ALWAYS, OR EVEN USUALLY) datsets will come prepackaged with extra information contained within each variable that will tell you some information about the variable and what the values are. We can access that information using the attributes function:
attributes(genfor.untouched$Q10A_1)
#> $label
#> [1] "[Abortion] What do you think is the most important problem facing this country?"
#>
#> $format.stata
#> [1] "%8.0g"
#>
#> $labels
#> No Yes
#> 0 1
attributes(genfor.untouched$Q10A_2)
#> $label
#> [1] "[National debt] What do you think is the most important problem facing this country?"
#>
#> $format.stata
#> [1] "%8.0g"
#>
#> $labels
#> No Yes
#> 0 1
attributes(genfor.untouched$Q10A_16)
#> $label
#> [1] "[Taxes] What do you think is the most important problem facing this country?"
#>
#> $format.stata
#> [1] "%8.0g"
#>
#> $labels
#> No Yes
#> 0 1So it’s the same question, just split across multiple columns, where each column represents a different issue.
(Most of the time this information about variables will be contained in a separate pdf “codebook”.)
So we’re going to want to collapse these 22 columns into one. To do that we’ll use the pivot_longer() function, to move these data with respect to this variable into a long format.
We have to tell it the columns we are converting into a long format, what the name of the new variable will be that we are creating that will contain the current columnb names, and what the name of the new variable will be that we are creating to contain the current values that are spread across columns.
genfor <- pivot_longer(genfor,
cols = "Q10A_1":"Q10A_22",
names_to = "top.issue",
values_to = "val")Now let’s see what we have:
nrow(genfor)
#> [1] 41272
#View(genfor)We went from 1876 rows to tens of thousands
We’ve transferred the unit of observations into individual issue-importance level. For each individual we have a row for how they answered the issue importance question.
We need to get rid of all those extra rows. We’re not actually interested in when a person does not care about an issue. So we can drop all the rowswhere ‘val’ is zero:
genfor <- genfor[genfor$val != 0,]
nrow(genfor)
#> [1] 2149That got us most of the way there, but we’ve still got more rows than we should? What’s going on?
#View(genfor)All the people who didn’t answer the question were coded as 99 for every issue. So now there’s 22 rows for each of those people.
What we want is one row per person. We’ll use the duplicated() function to do this. This function takes a vector and returns a FALSE if it’s the first time this value has shown up in the vector, and a TRUE if it’s appeared before.
head(duplicated(genfor$GENF_ID))
#> [1] FALSE FALSE FALSE FALSE FALSE FALSEIf we use the ! to flip the TRUEs and FALSEs, then we’ll have a vector we can use to ensure that we only have one row per person:
genfor <- genfor[!duplicated(genfor$GENF_ID),]
head(genfor)
#> # A tibble: 6 × 16
#> GENF_ID WEIGHT1 Q0 Q1 partyid7 date duration device
#> <dbl> <fct> <dbl> <dbl> <dbl> <chr> <dbl> <chr>
#> 1 7.93e8 0.4921… 2 2 5 2017… 11 Deskt…
#> 2 7.94e8 1.2025… 4 5 4 2017… 5 Smart…
#> 3 7.96e8 0.1318… 1 5 3 2017… 11 Smart…
#> 4 8.03e8 0.8249… 2 2 7 2017… 8 Smart…
#> 5 8.10e8 0.2149… 4 4 2 2017… 45 Smart…
#> 6 8.13e8 0.8648… 1 5 1 2017… 8 Smart…
#> # ℹ 8 more variables: gender <dbl>, age <dbl>, educ <dbl>,
#> # state <chr>, democratic <int>, republican <int>,
#> # top.issue <chr>, val <dbl>Now we have one last step. We don’t need to keep both ‘top.issue’ and ‘val’. ‘top.issue’ gives us all the information we need, except for the people who were 99’s in ‘val’. So let’s set ‘top.issue’ to NA for those people, and then we can drop the ‘val’ variable.
genfor$top.issue[genfor$val == 99] <- NA
genfor$val <- NULL 6.2.3 Cleaning column names
What are some of the issues with our column names?
names(genfor)
#> [1] "GENF_ID" "WEIGHT1" "Q0" "Q1"
#> [5] "partyid7" "date" "duration" "device"
#> [9] "gender" "age" "educ" "state"
#> [13] "democratic" "republican" "top.issue"Remember that the column names are simply stored as a character vector in one of the attributes of a dataframe.
We can manipulate this attribute just like any other attribute of an object.Let’s use the tolower() function to convert all the column names to lowercase:
Now let’s give some of the other variables more descriptive names.
names(genfor)
#> [1] "genf_id" "weight1" "q0" "q1"
#> [5] "partyid7" "date" "duration" "device"
#> [9] "gender" "age" "educ" "state"
#> [13] "democratic" "republican" "top.issue"
attributes(genfor.untouched$Q0) # this one is 2016 presidential vote
#> $label
#> [1] "Did you vote for Hillary Clinton, Donald Trump, someone else, or not vote in the 2016 presidential election?"
#>
#> $format.stata
#> [1] "%8.0g"
#>
#> $labels
#> Hillary Clinton
#> 1
#> Donald Trump
#> 2
#> Someone else
#> 3
#> Did not vote in the 2016 presidential election
#> 4
#> SKIPPED ON WEB
#> 98
#> refused
#> 99
attributes(genfor.untouched$Q1) # this one is Trump approval
#> $label
#> [1] "Overall, do you approve, disapprove or neither approve nor disapprove of the way that President Donald Trump is doing his job?"
#>
#> $format.stata
#> [1] "%8.0g"
#>
#> $labels
#> Strongly approve
#> 1
#> Somewhat approve
#> 2
#> Neither approve nor disapprove
#> 3
#> Somewhat disapprove
#> 4
#> Strongly disapprove
#> 5
#> SKIPPED ON WEB
#> 98
#> refused
#> 99We can rename things in this way. Accessing the particular entry in the names vector and assigning a new value
names(genfor)[2] <- "weight"
names(genfor)[3] <- "vote2016"
names(genfor)[4] <- "approve.trump"
names(genfor)[13] <- "approve.dem"
names(genfor)[14] <- "approve.rep"(We will see a slightly more robust way to do renaming when we get to the weeks on tidyr. This solution breaks down, for example, if in the future those index numbers don’t refer to those variables anymore.)
There are a few set conventions to creating variable names. First, R needs variables to start with a character. Second, it is convention to only use lower case characters for variable names. Third, words in your variable names should be separated with . or _. (I prefer ., but that’s just me.) Fourth, within reason it is better to have longer, more descriptive, variable names as opposed to shorter, confusing variable names.
I’ve got a personal pet-peeve about having underscores in column names. Let’s substitute the underscore in ‘genf_id’ for a period.
We’ll use gsub() to substitute the _ for a .
6.2.4 Recoding values in a vector or in the column of a dataframe
The first thing we want to do is make sure our variables are the correct type of data (i.e. character, numeric, logical, etc)
summary(genfor)
#> genf.id weight vote2016
#> Min. :7.926e+08 0.229665156 : 14 Min. : 1.000
#> 1st Qu.:2.571e+09 0.2958000119: 14 1st Qu.: 1.000
#> Median :4.293e+09 0.255285515 : 12 Median : 2.000
#> Mean :4.303e+09 0.305879976 : 12 Mean : 2.576
#> 3rd Qu.:6.048e+09 0.1508269493: 9 3rd Qu.: 4.000
#> Max. :7.875e+09 0.39396181 : 9 Max. :99.000
#> (Other) :1806
#> approve.trump partyid7 date
#> Min. : 1.000 Min. :-1.000 Length:1876
#> 1st Qu.: 3.000 1st Qu.: 2.000 Class :character
#> Median : 5.000 Median : 3.000 Mode :character
#> Mean : 4.721 Mean : 3.121
#> 3rd Qu.: 5.000 3rd Qu.: 4.000
#> Max. :99.000 Max. : 7.000
#>
#> duration device gender
#> Min. : 1 Length:1876 Min. :1.000
#> 1st Qu.: 9 Class :character 1st Qu.:1.000
#> Median : 14 Mode :character Median :2.000
#> Mean : 1184 Mean :1.531
#> 3rd Qu.: 82 3rd Qu.:2.000
#> Max. :19341 Max. :2.000
#> NA's :2
#> age educ state
#> Min. :18.00 Min. : 1.00 Length:1876
#> 1st Qu.:21.00 1st Qu.: 9.00 Class :character
#> Median :25.00 Median :10.00 Mode :character
#> Mean :25.15 Mean :10.28
#> 3rd Qu.:29.00 3rd Qu.:12.00
#> Max. :34.00 Max. :14.00
#>
#> approve.dem approve.rep top.issue
#> Min. :1.000 Min. :1.000 Length:1876
#> 1st Qu.:2.000 1st Qu.:3.000 Class :character
#> Median :2.000 Median :4.000 Mode :character
#> Mean :2.414 Mean :3.241
#> 3rd Qu.:3.000 3rd Qu.:4.000
#> Max. :4.000 Max. :4.000
#> NA's :242 NA's :277
class(genfor$weight)
#> [1] "factor"There’s something wrong with the ‘weight’ variable. It should be numeric, but it doesn’t have summary stats presented about it like the other numeric variables.
is.numeric(genfor$weight)
#> [1] FALSE
is.factor(genfor$weight)
#> [1] TRUESo the weight variable, which should be numeric, is being stored as a factor. A factor variable is a special type of variable that contains both numeric and descriptive information. To be honest: they are a bit of a holdover from older stats programs like STATA and SPSS. They will have some important functionality in regression, but for right now we need to change that so that we can properly use the weights.
The obvious (but annoyingly wrong) way to do this would simply be to use the as.numeric() function to change the weights into numbers. But if you apply as.numeric() to a factor variable, it converts all the values to their arbitrary numeric values rather than their meaningful labels.
head(as.numeric(genfor$weight)) # wrong
#> [1] 733 1172 138 992 319 1010We can get around this problem by first converting the weights into characters and then converting the character strings into numeric
head(as.numeric(as.character(genfor$weight)))
#> [1] 0.4921835 1.2025738 0.1318494 0.8249130 0.2149079
#> [6] 0.8648718I can’t tell you how frustratingly common this issue is, which is why I’m point it out now. You’re most likely to encounter it when you read in a dataset from a spreadsheet, and R turns some of your columns into factors rather than numeric.
We can confirm that this was the right choice by looking at a summary of the two attempts:
summary(as.numeric(genfor$weight))
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 1.0 366.8 716.5 765.1 1162.2 1627.0
summary(as.numeric(as.character(genfor$weight)))
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 0.01762 0.24216 0.47743 1.00000 1.18315 10.69962So now let’s store the corrected weights in the dataset:
genfor$weight <- as.numeric(as.character(genfor$weight))Let’s fix the date:
head(genfor$date)
#> [1] "2017-10-27" "2017-10-27" "2017-10-26" "2017-10-29"
#> [5] "2017-11-01" "2017-10-29"
class(genfor$date)
#> [1] "character"
genfor$date <- ymd(genfor$date)
class(genfor$date)
#> [1] "Date"This is particularly useful if you’re interested in subsetting the data based on the dates. Let’s say I just want to look at the people who completed in November:
table(genfor$date)
#>
#> 2017-10-26 2017-10-27 2017-10-28 2017-10-29 2017-10-30
#> 542 390 107 246 229
#> 2017-10-31 2017-11-01 2017-11-02 2017-11-03 2017-11-04
#> 103 100 44 41 12
#> 2017-11-05 2017-11-06 2017-11-07 2017-11-08 2017-11-09
#> 18 10 15 7 11
#> 2017-11-10
#> 1
#View(genfor[genfor$date >= "2017-11-01",])6.2.5 Recoding and replacing values
The most common form of data cleaning is recoding variables. There are tons of different ways to do this in R.
The most basic is recoding by taking advantage of the bracket notation.
Let’s work on recoding the vote2016 (formerly Q0) variable, which is a question about 2016 presidential vote
table(genfor$vote2016)
#>
#> 1 2 3 4 98 99
#> 896 262 213 497 6 2
attributes(genfor.untouched$Q0)
#> $label
#> [1] "Did you vote for Hillary Clinton, Donald Trump, someone else, or not vote in the 2016 presidential election?"
#>
#> $format.stata
#> [1] "%8.0g"
#>
#> $labels
#> Hillary Clinton
#> 1
#> Donald Trump
#> 2
#> Someone else
#> 3
#> Did not vote in the 2016 presidential election
#> 4
#> SKIPPED ON WEB
#> 98
#> refused
#> 99So let’s set the 98 and 99 responses to missing
genfor$vote2016[genfor$vote2016 %in% c(98,99)] <- NA
summary(genfor$vote2016)
#> Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
#> 1.000 1.000 2.000 2.166 4.000 4.000 8
table(genfor$vote2016)
#>
#> 1 2 3 4
#> 896 262 213 497Similarly can use characters to recode
genfor$vote2016[genfor$vote2016==1] <- "Clinton"
genfor$vote2016[genfor$vote2016==2] <- "Trump"
genfor$vote2016[genfor$vote2016==3] <- "Other"
genfor$vote2016[genfor$vote2016 %in% c(4,98,99)] <- NA
table(genfor$vote2016)
#>
#> Clinton Other Trump
#> 896 213 262
head(genfor$vote2016)
#> [1] "Trump" NA "Clinton" "Trump" NA
#> [6] "Clinton"Clean data often has labels that are more descriptive than just arbitrary numbers. So we might recode the gender variable:
attributes(genfor.untouched$gender)
#> $label
#> [1] "Respondent gender"
#>
#> $format.stata
#> [1] "%8.0g"
#>
#> $labels
#> Unknown Male Female
#> 0 1 2
genfor$gender[genfor$gender == 1] <- "M"
genfor$gender[genfor$gender == 2] <- "F"
genfor$gender[genfor$gender == 0] <- "U"My personal preference, however, is to have indicator variables for categories like this.
genfor$female <- NA
genfor$female[genfor$gender=="M" | genfor$gender=="U"] <- 0
genfor$female[genfor$gender=="F"] <- 1This displays the same information, but in a way that we can do math on, which is helpful.
One last function… If a column contains information about more than one variable we might want to divide it into two columns using the separate() function.
Let’s imagine we wanted separate columns for year, month, and day that the respondent took the survey:
genfor2 <- separate(genfor,
col = "date",
into = c("year","month","day"))
head(genfor2)
#> # A tibble: 6 × 18
#> genf.id weight vote2016 approve.trump partyid7 year month
#> <dbl> <dbl> <chr> <dbl> <dbl> <chr> <chr>
#> 1 7.93e8 0.492 Trump 2 5 2017 10
#> 2 7.94e8 1.20 <NA> 5 4 2017 10
#> 3 7.96e8 0.132 Clinton 5 3 2017 10
#> 4 8.03e8 0.825 Trump 2 7 2017 10
#> 5 8.10e8 0.215 <NA> 4 2 2017 11
#> 6 8.13e8 0.865 Clinton 5 1 2017 10
#> # ℹ 11 more variables: day <chr>, duration <dbl>,
#> # device <chr>, gender <chr>, age <dbl>, educ <dbl>,
#> # state <chr>, approve.dem <int>, approve.rep <int>,
#> # top.issue <chr>, female <dbl>The function will attempt to automatically detect and guess the character that separates the columns. In this case it works just fine, but it’s not a bad idea to specify exactly what you want, so that it doesn’t make an unexpected mistake:
6.2.6 Analysis
Let’s look at doing a quick analysis. Let’s see how age relates to voting for Trump
Let’s first make a variable that is vote for trump (1) or not (0)
genfor$trump <- NA
genfor$trump[genfor$vote2016=="Trump"]<- 1
genfor$trump[genfor$vote2016!="Trump"]<- 0
table(genfor$trump)
#>
#> 0 1
#> 1109 262(remember this is a survey of millenials, so very few voting for trump)
How does age relate to voting for trump?
Making a scatterplot not very helpful here:
plot(genfor$age,genfor$trump)
Another possibility is a boxplot where we look at the distribution of ages for trump and not trump voters
boxplot(genfor$age ~ genfor$trump,
xlab="Vote for Trump",
ylab="Age",
main="Distribution of Age for Trump and Non-Trump Voters")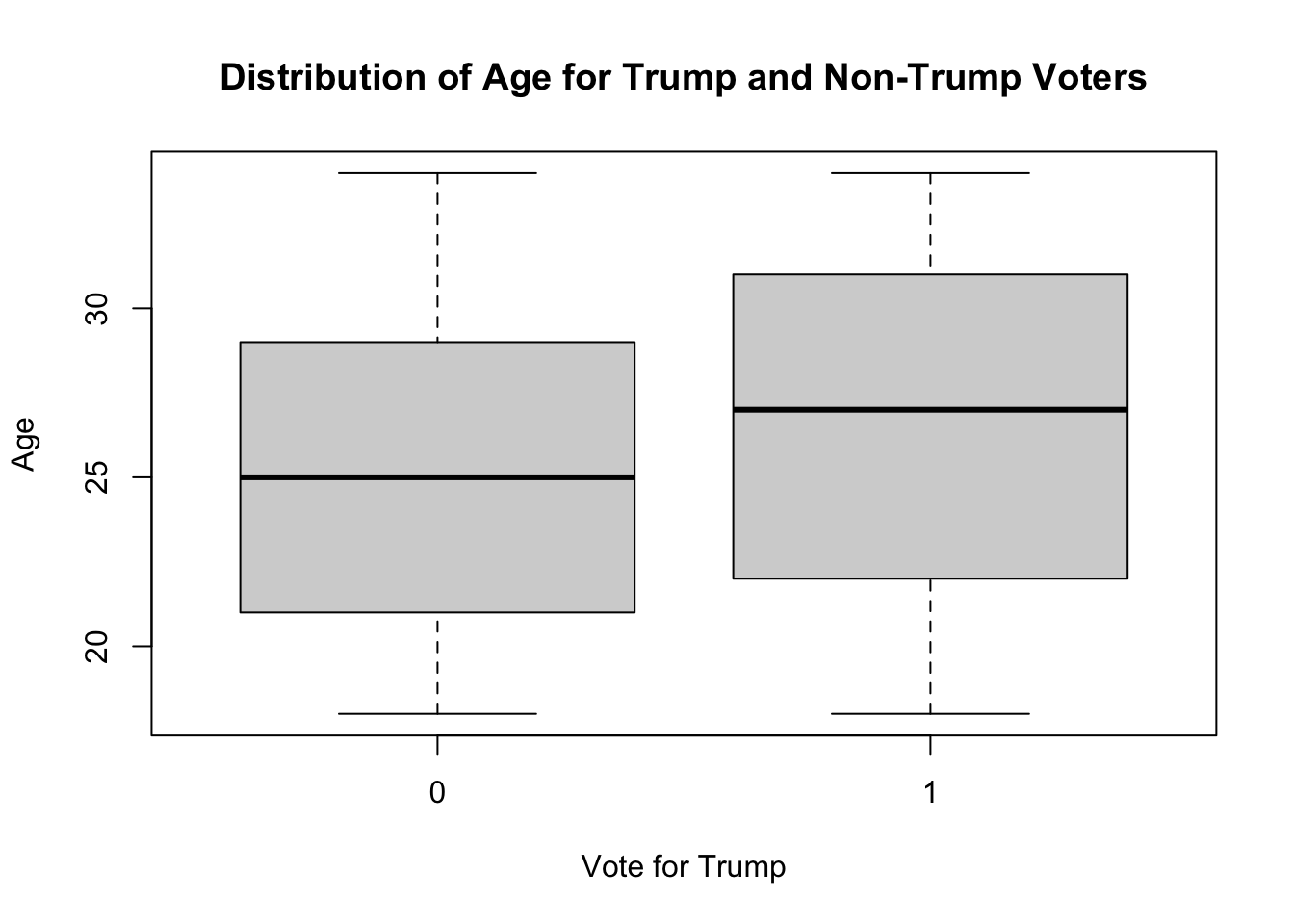
Can also look at the correlation
cor(genfor$age, genfor$trump)
#> [1] NA
cor(genfor$age, genfor$trump, use="pairwise.complete")
#> [1] 0.1280754Small positive correlation
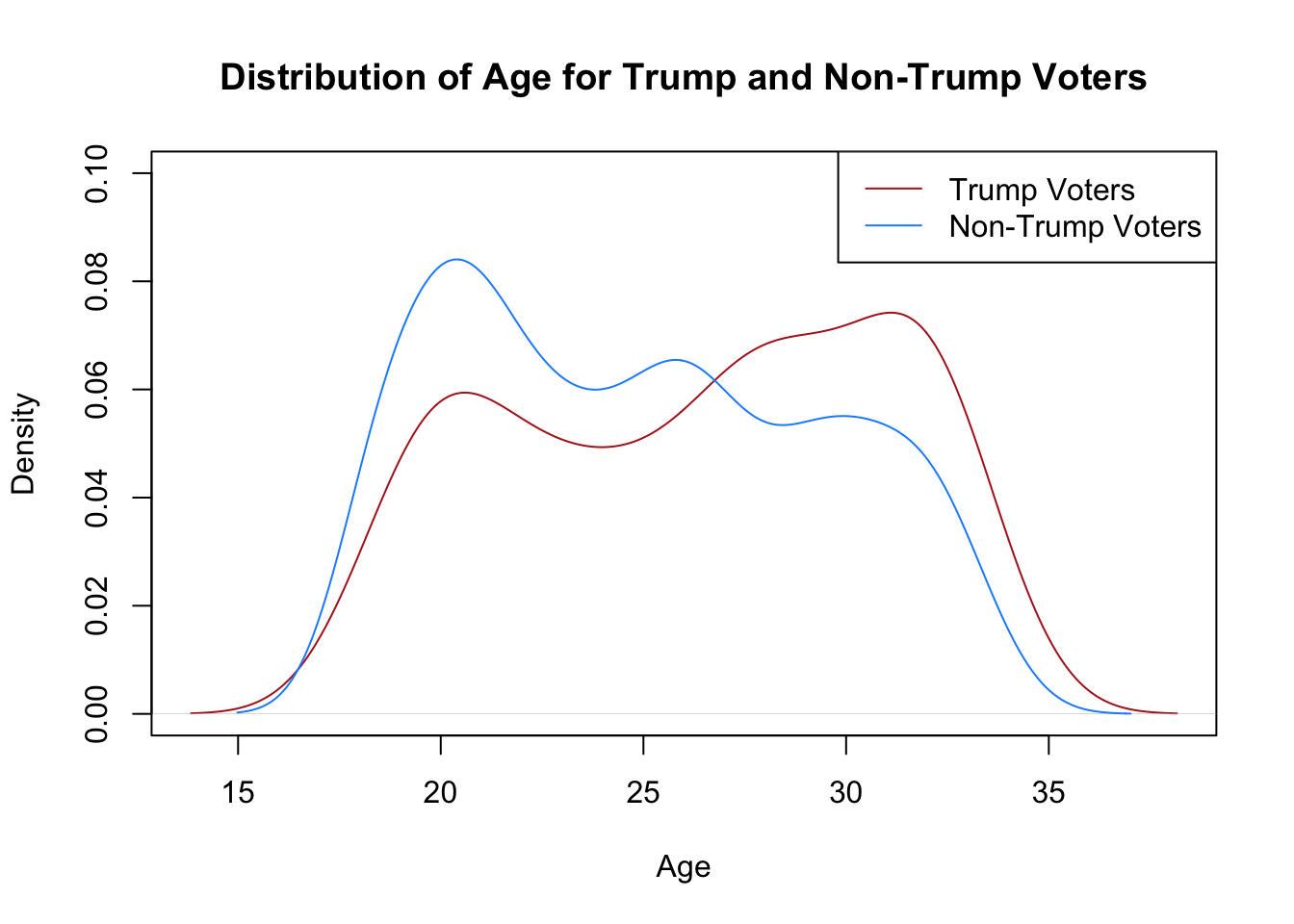
Another way to look at the distribution of age is a density plot
plot(density(genfor$age[genfor$trump==1],na.rm=T),
xlab="Age",
main="Distribution of Age for Trump and Non-Trump Voters",
col="firebrick",
ylim=c(0,0.1))
points(density(genfor$age[genfor$trump==0],na.rm=T), type="l",
col="dodgerblue")
legend("topright",c("Trump Voters","Non-Trump Voters"),
lty=c(1,1), col=c("firebrick","dodgerblue"))